Logging the conversation with Literal
First, we initialize the Literal client.Logging the steps
In this example we have 2 steps:semantic_search and generate_response. We can use the step decorator to log these steps.
Logging the run
Logging the thread
A thread is a sequence of steps that are related to each other. In our example, we have a single thread. To create a thread, we use thethread decorator.
Logging the user question and final answer
Finally, we can log the user question and the final answer usingclient.message.
Full code
Running the example in Python
To run the example, you need to install the Literal client: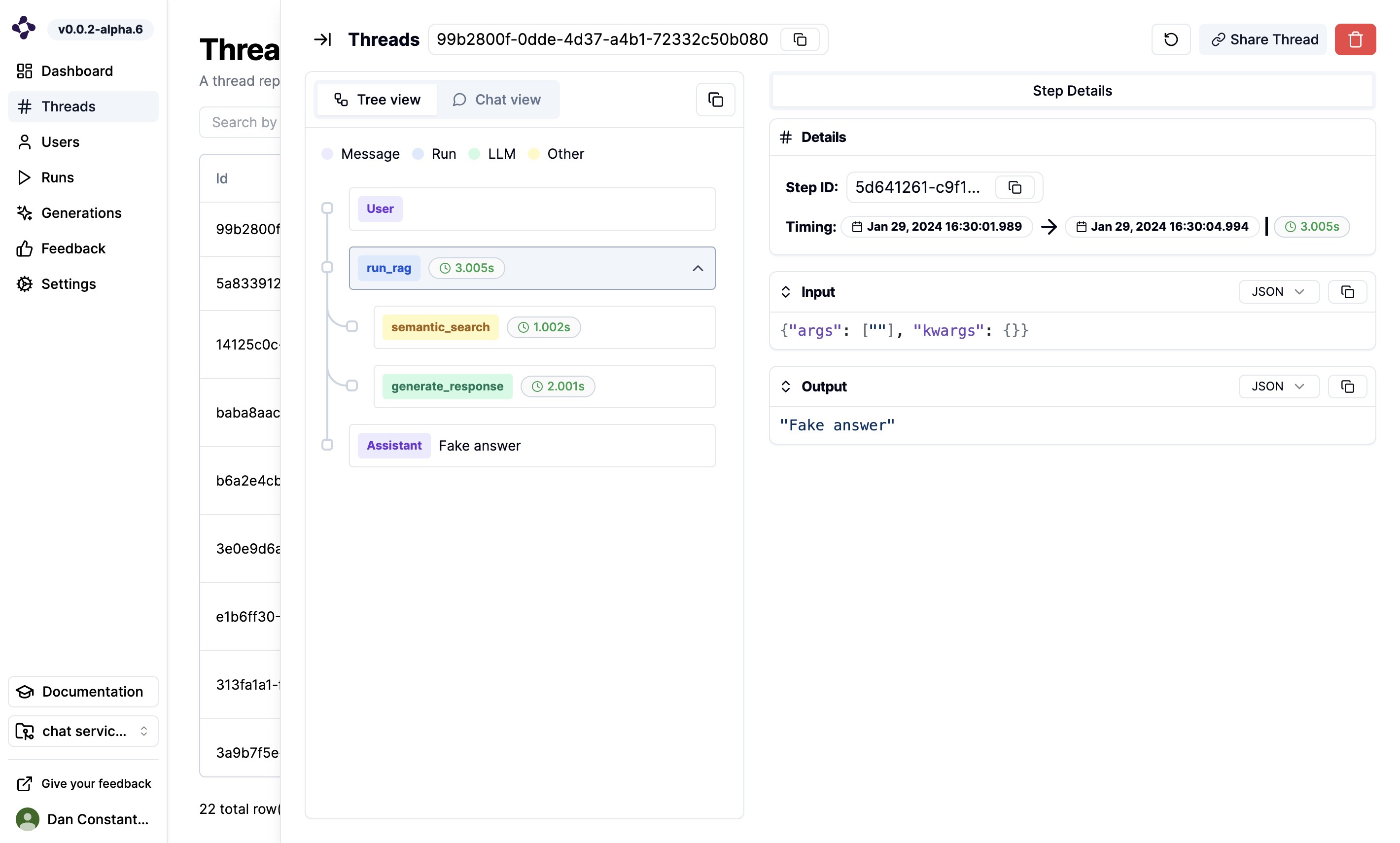
Rendering of the Thread